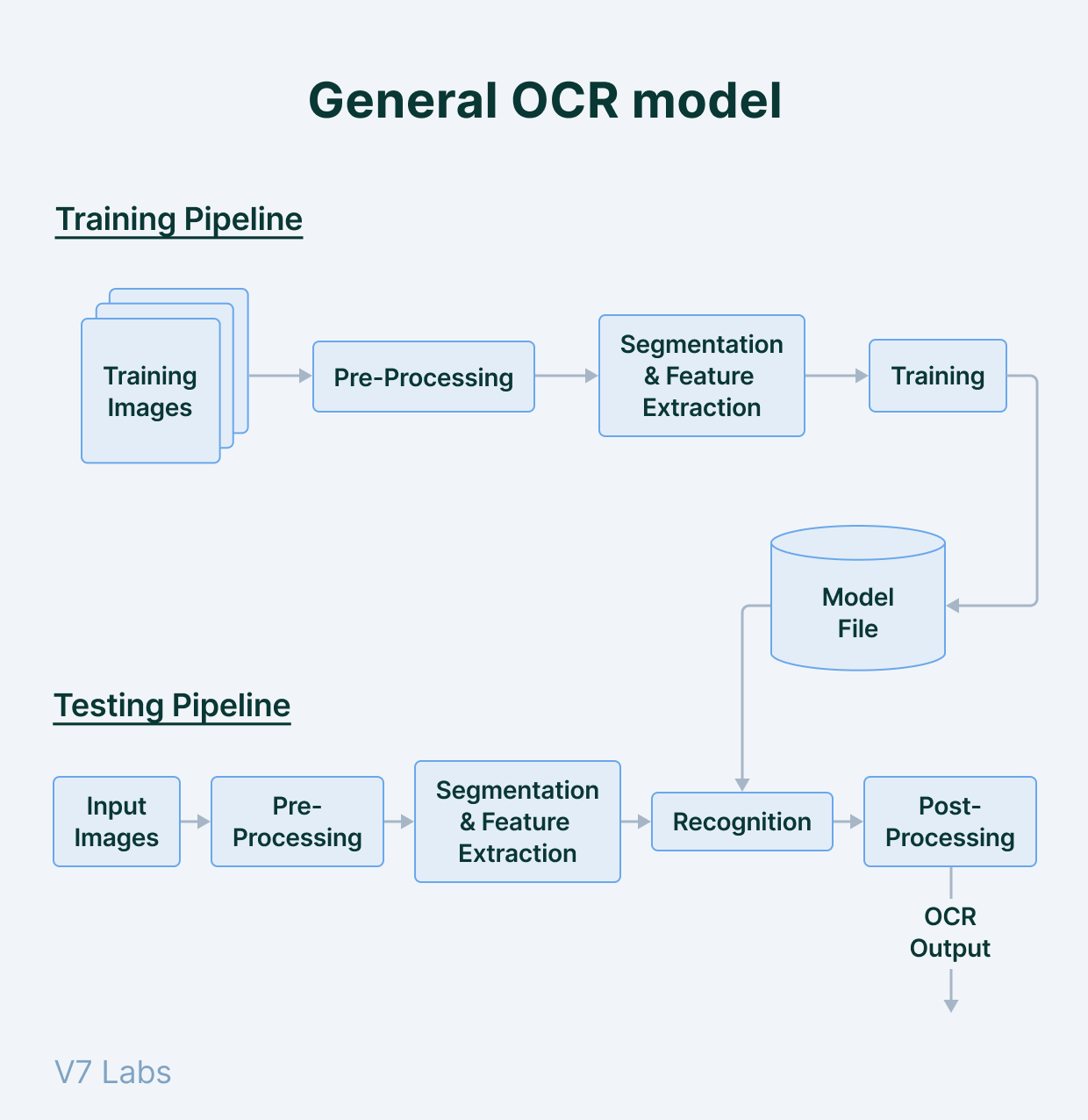
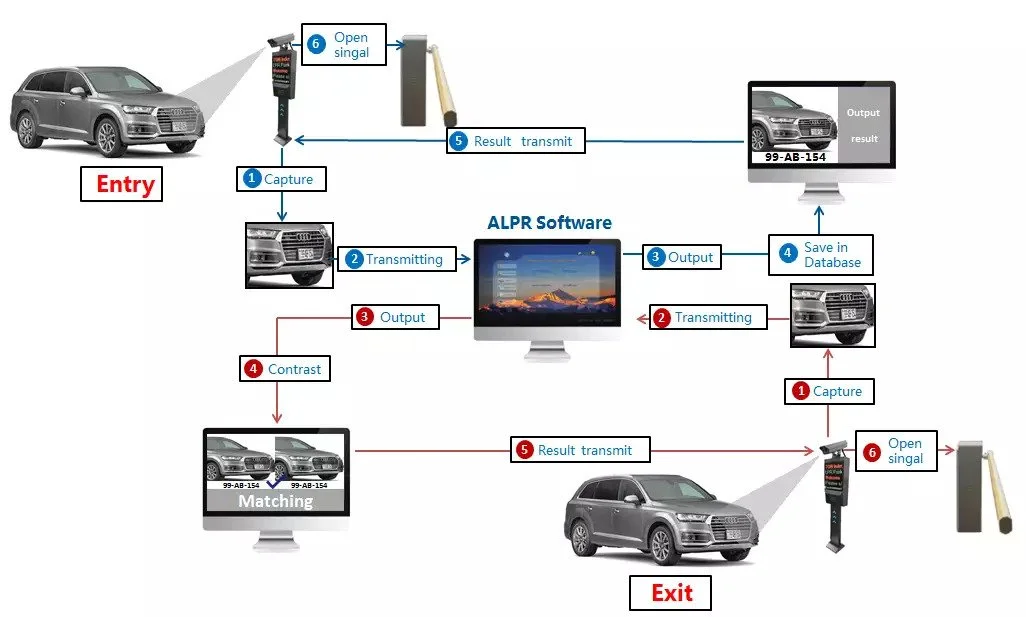
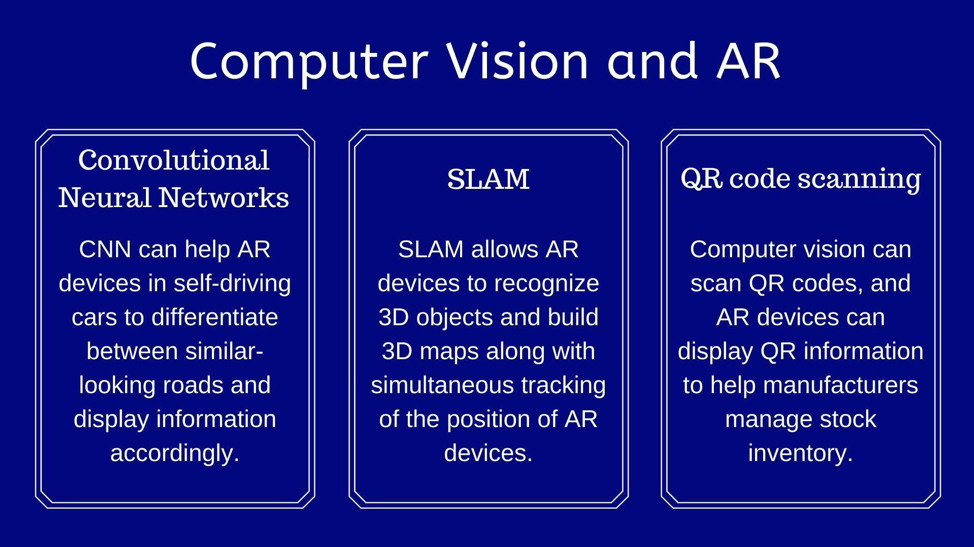
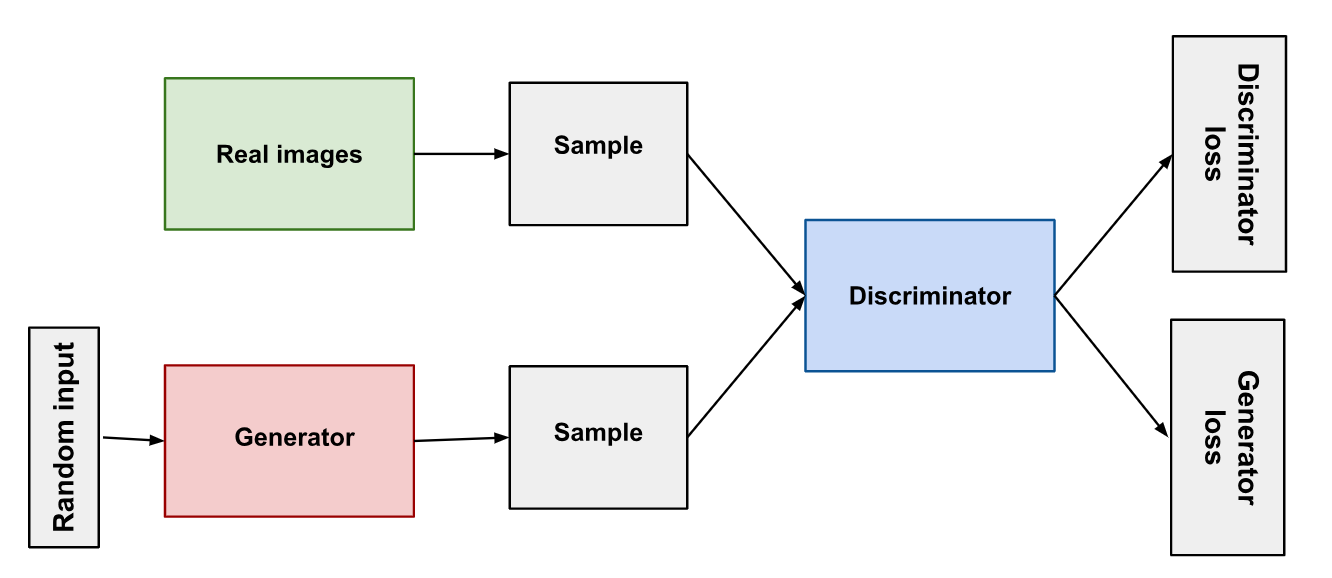
Human Pose Estimation

Introduction: Human pose estimation is a fascinating application of computer vision that involves detecting and tracking the positions of various parts of the human body. By analyzing visual data, computer vision algorithms can estimate the pose of a person in real-time, opening up numerous possibilities across diverse fields. In this article, we delve into the technology behind human pose estimation, explore the key algorithms involved, and highlight its applications in sports analysis, animation, and human-computer interaction. Understanding Human Pose Estimation: Key Concepts: Human pose estimation aims to determine the configuration of the human body, usually represented by a set of keypoints or landmarks corresponding to major joints (e.g., shoulders, elbows, knees, etc.). These keypoints form a skeleton model that captures the pose of the person. Types of Pose Estimation: 2D Pose Estimation: Estimates the positions of keypoints in a two-dimensional image plane. 3D Pose Estimatio...