Object Detection Techniques: SSD and YOLO
Introduction:
Computer vision covers a wide territory, but the task of object detection holds a special significance due to its wide range of practical uses. Whether it's helping self-driving cars navigate through bustling city streets or aiding security systems in identifying intruders, the ability to detect and pinpoint objects within images and videos is a crucial aspect of machine perception. In this blog post, we'll delve into the fascinating world of object detection and examine two commonly used methods: Single Shot Multi-Box Detector (SSD) and You Only Look Once (YOLO).
Exploring Object Detection Methods:
Single Shot Multi-Box Detector (SSD):
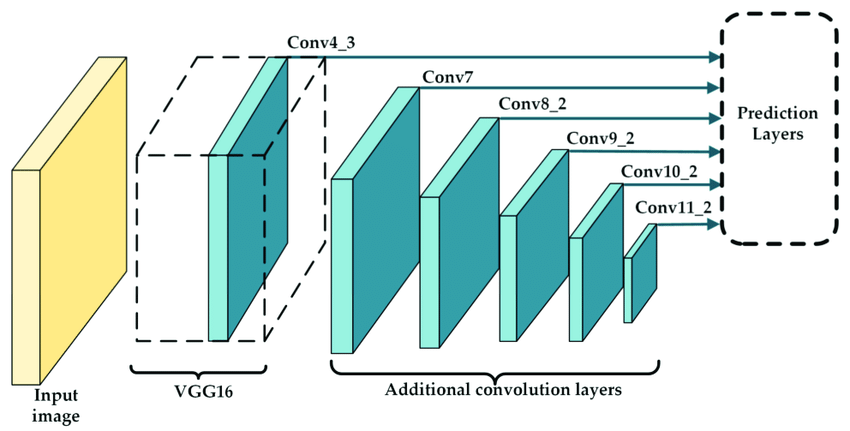
Key Components of SSD:
- Feature Pyramid: SSD leverages a feature pyramid to capture multi-scale features from input images. By extracting features at multiple resolutions, SSD can detect objects of various sizes and aspect ratios with greater accuracy.
- Convolutional Head: Following the feature extraction stage, SSD adds additional convolutional layers to predict bounding boxes and class probabilities at different spatial locations within the feature maps. These predictions are performed at multiple scales to handle objects of different sizes.
- Anchor Boxes: SSD uses anchor boxes, also known as default boxes, to predict object bounding boxes. These anchor boxes are defined at different aspect ratios and scales, providing a set of reference boxes that the model learns to adjust based on the input image.
- Loss Function: To train the SSD model, a combination of localization loss (e.g., Smooth L1 loss) and classification loss (e.g., cross-entropy loss) is used. The localization loss penalizes discrepancies between predicted and ground-truth bounding boxes, while the classification loss encourages accurate class predictions.
Advantages of SSD:
- Efficiency: SSD achieves real-time performance by performing object detection in a single forward pass of the network.
- Accuracy: By incorporating multi-scale features and anchor boxes, SSD achieves high detection accuracy across a wide range of object sizes and aspect ratios.
Code Snippet (using TensorFlow/Keras):
You Only Look Once (YOLO):
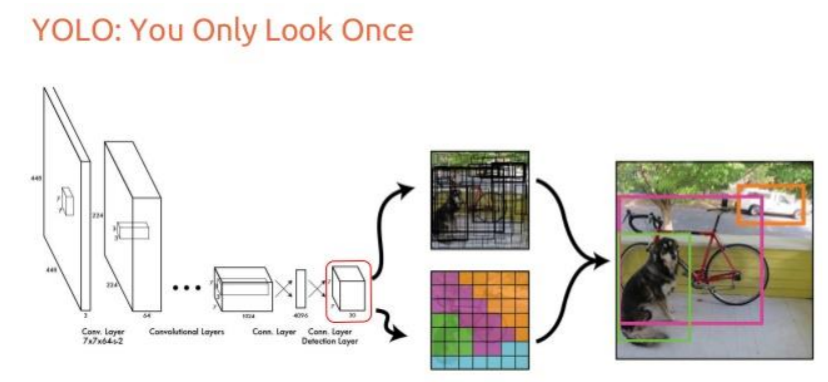
Key Features of YOLO:
- Unified Detection: YOLO takes a holistic approach to object detection by simultaneously predicting bounding boxes and class probabilities for all objects in the image. This unified detection strategy enables YOLO to achieve real-time performance.
- Grid Cell Representation: YOLO divides the input image into a grid of cells and predicts bounding boxes and class probabilities within each grid cell. Each cell is responsible for detecting objects whose center falls within its boundaries.
- Anchor Boxes: Similar to SSD, YOLO utilizes anchor boxes to improve localization accuracy. These anchor boxes are predefined with different aspect ratios and scales, allowing YOLO to adapt to objects of varying shapes and sizes.
- Loss Function: YOLO optimizes a combined loss function that penalizes localization errors (e.g., bounding box regression loss) and classification errors (e.g., softmax cross-entropy loss). By jointly optimizing both objectives, YOLO learns to predict accurate bounding boxes and class probabilities.
Advantages of YOLO:
- Speed: YOLO achieves real-time performance by processing the entire image at once, eliminating the need for complex post-processing steps.
- Simplicity: YOLO's straightforward architecture makes it easy to implement and deploy, making it a popular choice for applications requiring fast and efficient object detection.
Applications of Object Detection:
Autonomous Vehicles:
The ability to detect objects is crucial for autonomous vehicles to effectively perceive and comprehend their surroundings. By successfully identifying and monitoring pedestrians, cars, and traffic signals, object detection technology enables safe navigation and intelligent decision-making on the road.
Surveillance and Security:
When it comes to surveillance and security, object detection plays a crucial role in identifying intruders, suspicious activities, and unauthorized objects. By constantly scanning video streams and analyzing detected objects, security systems are able to promptly notify authorities of possible threats.
Conclusion:
The critical role of object detection in the field of computer vision cannot be overstated, as its impact spans across various domains. With cutting-edge methods such as SSD and YOLO, machines are now able to discern and pinpoint objects with remarkable precision and speed. From powering the safety features of autonomous vehicles to fortifying security systems, the advancements in object detection technology drive constant progress and ingenuity in the realm of computer vision.


Comments
Post a Comment